
Big Data Multiclass Classification using Apache Spark
In this blog we have seen how to develop machine learning over multi-dimensional or multivariate dataset making multiclass classification and doing predictions for new data appearing to the system.
The scope & complexity of multi-class classification grows to a far extent when,
- Raw data size to be handled is growing huge. For example, twitter tweets or input data coming to Uber from its various front-end interfaces. These are data streaming use cases where Terabytes of data hourly/daily comes into central engine of the system for processing, doing analytics, learning over it.
- In reality such data set often has multiple dimensions or properties and also each data record won’t have all of these properties present but only few of them.
This is a Big Data Machine Learning problem statement, where there needs to be continuous learning using past arrived data to keep making classification model robust and do new instant predictions for new data arriving to system so that analytics results, reports can be presented almost real-time.
To handle massive quantities of data the processing engine needs to be certainly based on distributed computing as well as designed using a suitable data processing architecture to handle load, continuous learning, real-time computation doing prediction, analysis and reports.
This article aims towards describing gist of multi-dimensional multi-class big data-set classification using Apache Spark with its Python code snippet. Before looking into it let’s touch base over Apache Spark and an example big data processing architecture which can be leveraged for doing multi-class classification of multivariate huge data.
Apache Spark
Apache Spark is well known open-source cluster-computing framework, a lightning-fast unified analytics engine for large-scale data processing. Spark analytics platform became more popular over Hadoop MapReduce in general due to variety of benefits it provides.
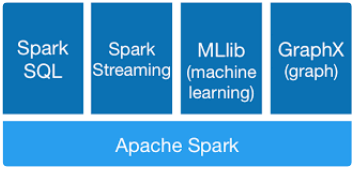
- Apache Spark has built-in stack of libraries as shown above
- Supporting simple SQL interface to query structured data and process over large cluster
- Spark Streaming makes it easy to build scalable fault-tolerant streaming applications
- GraphX API for graphs and graph-parallel computation
- MLlib for scalable machine learning
- Spark RDD (Resilient Distributed Data-sets) which enables in-memory fault tolerant distributed computations, DAG (Directed Acyclic Graph) based scheduling and query optimization technique makes it a way performant for batch as well as streaming computations.
- Apache spark org claims Logistic Regression works 100x faster than compare to Hadoop.
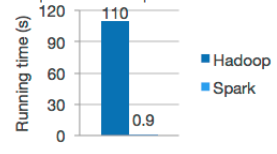
- Apache spark org claims Logistic Regression works 100x faster than compare to Hadoop.
- Spark based applications are easy to program and has choice of using different programming languages like Java, Python, Scala, R and SQL
- Ultimately Spark infrastructure can be hosted over its own cluster, Hadoop YARN, EC2 or container orchestration systems like Kubernetes and Apache Mesos. As well as offers smooth integrations with number of open-source databases, streaming apps and file formats.
Lambda Architecture
Lambda Architecture is a generic, scalable data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. Lambda architecture describes a system consisting of three layers: batch processing, speed (or real-time) processing, and a serving layer for responding to queries. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data.
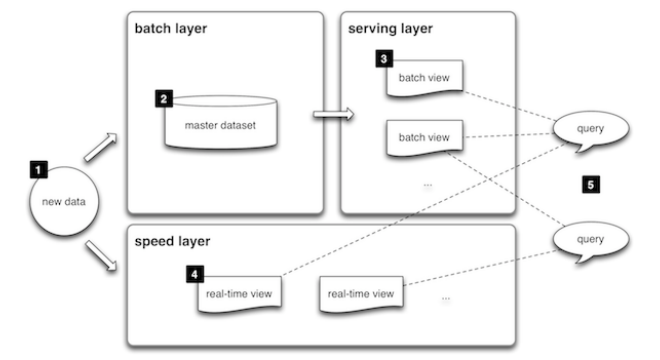
The architecture does not enforce on a particular technology stack but traditionally for batch processing Hadoop technologies are used while for instance, speed layer constitutes technologies like Apache Storm to process Kafka streams at real-time and both the layers output is further consolidated into serving layer HBase database to query from.
In Lambda Architecture, Apache Spark can be well utilized to implement both batch and speed processing layers using its in-memory fault tolerant computations and streaming capability. As well as for machine learning use case like multivariate dataset classification Spark’s MLlib can be readily used for building multi-class classification model through batch-processing. Spark streaming@speed layer can leverage this trained classification model to make real-time prediction for new data. This Apache Spark based batch layer shall periodically keep on updating classification model though repetitive batch processing. This shall help making the model accuracy more robust over the time.
Classification using Spark MLlib
Classification targets dividing data items into different classes by learning dataset properties. Commonly there are two types of classification, binary classification and multiclass classfication. As these names suggest, in binary classification there are only two categories while in multiclass there can be more than two categories.
Spark MLlib supports two linear methods for classification: linear Support Vector Machines (SVMs) and logistic regression. Linear SVMs supports only binary classification and it is more tuned for it, while logistic regression supports both binary and multiclass classification problems. Logistic regression has a multinomial logistic regression specification which is used for multiclass classification problems.
In this blog we have seen a code snippet for classifying Iris flower multivariate dataset using scikit-learn python library. Using this same multivariate Iris dataset to demonstrate multinomial logistic regression using Spark MLlib.
Iris has 3 species of it (Setosa/Versicolor/Virginica). This classification is based on the flower sepal and petal length-width measurement. For example,
| Sepal Length | Sepal Width | Petal Length | Petal Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Iris setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | Iris versicolor |
| 6.7 | 3.0 | 5.2 | 2.3 | Iris virginica |
We do have just 150 records in this multivariate dataset and can be downloaded from here
The code snippet shown below uses Spark Python API (PySpark). PySpark can be deployed using “pip install pyspark” command. Please check this link for complete details on Spark deployment.
Also for demonstration purpose using local system all available CPU cores to run Spark parallel jobs. Where in Lambda architecture, the Python application will be running over either spark standalone cluster, Hadoop YARN or Kubernetes setup processing Terabytes of multivariate data-set periodically.
Let’s open a new Python code file named LogisticRegression_Using_Spark_ML.py in your favorite text editor. You can also use any Python editor like pycharm, Canopy to compile and run the program.
Note: You can execute the program from command line using “spark-submit LogisticRegression_Using_Spark_ML.py”
“””
This python code snippet shows how to do multivariate dataset multiclass classification in a Big Data environment using Apache Spark MLlib.
“””
from pyspark import SparkConf, SparkContext
from pyspark.mllib.classification import LogisticRegressionWith LBFGS, LogisticRegressionModel
from pyspark.mllib.regression import LabeledPoint
from numpy import array
# — Declarations —
iris_species = [‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’]
# — Functions —
def mapSpeciesType(species_name):
if species_name == ‘Iris-setosa’:
return 0
elif species_name == ‘Iris-versicolor’:
return 1
elif species_name == ‘Iris-virginica’:
return 2
# Convert a list of raw fields from our CSV file to a LabeledPoint that Spark MLlib can use.
# All data must be numerical.
def createLabeledPoints(fields):
sepal_length = float(fields[0])
sepal_width = float(fields[1])
petal_length = float(fields[2])
petal_width = float(fields[3])
species = mapSpeciesType(fields[4])
return LabeledPoint(species, array([sepal_length, sepal_width, petal_length, petal_width]))
# — Main Code —
# Boilerplate spark stuff
conf = SparkConf().setMaster(“local[*]”).setAppName(“Multivariate-Dataset-Classification”)
sc = SparkContext(conf=conf)
sc.setLogLevel(“ERROR”)
# Load Iris input data
rawData = sc.textFile(‘/spark/sampledata/iris.data’)
# Load data parameters from the raw data by splitting line by comma delimiters
csvData = rawData.map(lambda x: x.split(“,”))
# Convert these lists into LabeledPoints
trainingData = csvData.map(createLabeledPoints)
# Train the multinomial logistic regression model
mcm = LogisticRegressionWithLBFGS.train(trainingData, iterations=10, numClasses=len(iris_species))
# Predicting single data item class; useful in streaming to process individual item
print(iris_species[mcm.predict([4.9876, 3.348, 1.8488, 0.2])])
print(iris_species[mcm.predict([5.3654, 2.0853, 3.4675, 1.1222])])
print(iris_species[mcm.predict([5.890, 3.33, 5.134, 1.88])])
# Predicting data items classification in batch mode by distributing work across the nodes
testIris = [array([4.9876, 3.348, 1.8488, 0.2]), array([5.3654, 2.0853, 3.4675, 1.1222]), array([5.890, 3.33, 5.134, 1.88])] testData = sc.parallelize(testIris)
# Let’s try out prediction for our iris test data in batch
print(‘\nIris prediction for batch data:’)
predictions = mcm.predict(testData)
results = predictions.collect()
for result in results:
print(iris_species[result])
# Evaluating the model on training data itself
trainErr = labelsAndPreds.filter(lambda lp: lp[0] != lp[1]).count()/ float(trainingData.count())
print(“Training Error = ” + str(trainErr))
# Save and load model
mcm.save(sc, “/junk/pythonLogisticRegressionWithLBFGSModel”)
sameModel = LogisticRegressionModel.load(sc, “/junk/pythonLogisticRegressionWithLBFGSModel”)
print(“\nContinue prediction with reloaded model…”)
print(iris_species[mcm.predict([5.890, 3.33, 5.134, 1.88])])
Here is the code flow explanation:
-
First, import required Python modules.
-
SparkContext & SparkConf: Every Spark application has a driver program associated with it and this driver program uses SparkContext object which drives Spark application execution. Where, SparkConf object is to be configured for right properties. For instance, setting application name or defining execution environment (local or specific cluster environment).
-
LogisticRegressionWithLBFGS, LogisticRegressionModel: LogisticRegressionWithLBFGS module from pyspark.mllib.classification is being used for multi-class classification purpose. LBFGS (Limited memory BFGS) method is particularly well suited for optimization of problems with a large number of variables.
-
LabeledPoint: It is a datatype that Spark MLlib algorithms understand to process. As it sounds like, it is a point that has some sort of label associated with it that conveys meaning of this data in human readable terms.
-
numpy.array: Sophisticates managing N-dimensional array object.
-
-
The main code starts with standard boilerplate spark context initialization. SparkContenxt is initialized using configuration to run spark jobs only on local host using all available cpu cores (local[*]).
Setting loglevel to ERROR so that when the program is executed over console using “spark-submit”, it does not clutter console output with a lot of spark info messages and program output can be seen clearly.
-
Using sparkcontext object load iris raw data.
If you open Iris data file (download from above given link), it has below format:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
Each line stands for one record and one record has 5 fields (sepal-len, sepalwidth, petal-len, petal-width, Species Name) separated by comma. Using sparkcontext textFile() method, a new RDD (Resilient Distributed Dataset) of name rawData is created from this Iris data text file, where each entry, each line of the RDD, consists of one line of input.
-
Now need is to learn about the 5 data parameters out of this raw data records so using Spark map() method to process rawData RDD across available CPU cores where RDD parts are getting processed in parallel to go through each record and split that by comma (,) leveraging Python lambda function. Output of map() is another RDD named csvData.
-
Further on csvData RDD, another map() is being invoked to create training data set which Spark MLlib LogisticRegressionWithLBFGS can understand to do learning out of it. To do this, createLabeledPoints() util function is defined which converts each Iris record parameters into LabeledPoint data type. In cluster deployment, all this map() and data conversion, filtering tasks are going to be executed on number of cluster nodes and eventually on a large set of CPU cores. That makes big data processing fast.
-
createLabeledPoints() method receives list type object which has 5 fields. It uses them to create one LabeledPoint record for each entry. Make a note that LabeledPoint creation needs all data in number format. sepal-len, sepal-width, petal-len, petal-width are all float type entries but not species names which are strings. So this method further utilizes mapSpeciesType() method to convert Iris species names into number format. LabeledPoint now maps this species number to array of that record attributes which next to be used for building classification model.
-
-
With the training data ready, train the multinomial logistic regression model using LogisticRegressionWithLBFGS algorithm. Here using only 10 iterations which algorithm takes to converge as dataset has only few records. By default there are 100 iterations. Generally you need to play with such properties of machine learning algorithm/s to tune it for particular training dataset. numClasses denotes number of possible outcomes for k classes classification. Output of this train() method is multi-class classification model which can be used to do Iris species predictions for new incoming data.
-
mcm.predict([4.9876, 3.348, 1.8488, 0.2])]
Here [4.9876, 3.348, 1.8488, 0.2] numbers array denotes a new Iris flowers data [sepal-len, sepal-width, petal-len, petal-width] using which its type needs to be predicted. The model object has predict() function that returns class label in integer fashion. This output number is then converted to readable type string using iris_species name list.
This single data items prediction can be used in lambda architecture speed layer to classify continuous flowing data stream.
Iris-setosa
Iris-versicolor
Iris-virginica
-
New data prediction can also be done in batch mode by creating RDD of new data items and run prediction algorithm across the available CPU cores using the classification model. The jobs execute in parallel like Spark map() function. Finally, using collect() call the prediction results are collected from all the concurrently executed jobs to print predicted Iris class labels.
Note: Make a note that Spark has two types of high level RDD operations called as Transformation and Action. You can refer Spark documentation for more details about this. For instance map() is transformation type method where collect() is Action type. Here point is, Spark does not actually execute transformation jobs until and unless Action job is triggered over that RDD. In meanwhile Spark using its DAG (Directed Acyclic Graph) scheduling technique it better optimizes execution algorithm of the transformation job.
Output:
Iris prediction for batch data:
Iris-setosa
Iris-versicolor
Iris-virginica
-
How to evaluate the model score?
-
Further 2-3 lines code shows how can we measure the classification model accuracy by again leveraging Spark concurrent job execution. Ideally for measuring model score, one shall use dataset reserved for testing purpose (which is separate than the one used for model training purpose) but here the same whole training dataset is used to find out model error component. Smaller the error number (-> to zero) better model accuracy is.
-
So over trainingData RDD, having LabeledPoint data, a map() function is executed which transforms RDD data item into a list type object where original Iris type name is preserved as it is and classification model predicted Iris type name is stored as second parameter. Next a filter() method is executed over this transformed RDD to count mismatch between original Iris species type and predicted species type. This count divided by total entries gives training error which comes around 0.04 which is indeed low, signifies that the classification model is robust.
-
Training Error = 0.04
-
Save and load model
-
As mentioned earlier, Lambda Architecture suggests to re-execute batch layer jobs periodically to recompute results from scratch. This helps avoiding errors which can introduce through only incremental compute. For creating machine learning classification model, this re-compute technique can be used using whole dataset including sufficient latest newly arrived data. It is recommended that once the model is created you preserve it over persistent storage so that it can be reloaded quickly, for instance, machine or Spark driver application restart case. Last a couple of lines show how to preserve built multi-class LogisticRegression classification model over given file system directory and also reloaded back to resume predictions
-
Continue prediction with reloaded model…
Iris-virginica
Summary
This article covers gist of handling multivariate big data multi-class classification using solid cluster computing engine, Apache Spark and its machine learning API, MLlib. Also we have touch based over benefits of Apache Spark and how it can be leveraged in a robust big data processing architecture like Lambda Architecture.
Thank you !!!
© 2018 Isana Systems